- 並列処理性能とその効率について以下の設問に答えよ。
ある処理を1台のプロセッサで実行した時、T1 [sec]で終了する。この処理が完全並列化可能(逐次部分は無視できる)である時、p台のプロセッサでの実行を考える。この処理は完全並列化は可能であるが、p台のプロセッサで並列処理する際、Tcomm(p) [sec]だけの通信時間がオーバヘッドとして発生するとする(通信時間はpの関数である)。
- この問題をp台のプロセッサで処理する際の速度向上率s(p)と、並列化効率e(p)を式で表せ。
- Tcomm(p)がpに比例し、Tcomm(p)=αpと表せたとする。並列化効率を80%以上に保つには、αはどのような値でなければならないか。T1とpを用いて表せ。
- 通信時間を決定するファクタであるαの条件について、T1を問題規模、pを並列度と捉え、論ぜよ。
- 3次元の物理問題領域のサイズがN3であるとする。これをn3台のプロセッサでdomain decompositionにより並列処理する。この時、問題領域を特定の1つの次元方向でのみ分割する方法(スライス状分割)と、3つの次元全てに渡って分割する方法(サイコロ状分割)が考えられる。講義資料23ページにあるように、全要素の値を更新する際、互いに隣合う要素の値を参照するとする(ただし資料では1次元空間だがここでは3次元空間とする)。計算量と通信量の観点から、スライス状分割とサイコロ状分割のどちらが一般的に有利であるか論ぜよ。
- 実際に構築された大規模並列計算機(講義資料で取り上げたもの、あるいはその他)のうち1台を選び、規模・性能・アーキテクチャ的特徴について詳細を調べてまとめよ。調査にはweb等を活用することを薦めるが、全て出展(URL等)を明らかにすること。
- IntelのXeonシリーズCPUと、AMDのOpteronシリーズCPUは、現在共にx86アーキテクチャに基づくマルチコアプロセッサとして広く用いられている。しかし、XeonはSMPアーキテクチャ、OpteronはNUMAアーキテクチャを持ち、その性質は異なる。メモリバンド幅、プログラミング上の注意等の観点から、両者を比較せよ。
- 並列処理ネットワークの理論ピークバンド幅は年々急激に増加している。しかし、一般的に、レイテンシの削減はそれほど急激には進まない。この結果として、プログラミングやアプリケーション上でどのような影響が現れるか論ぜよ。
- ナップサック問題とは、いくつかの荷物を袋に最大の値段になるように袋に詰める組合せを求める問題
- N個の荷物があり、個々の荷物の重さをwi、値段をpiとする。袋(knapsack)には最大Wの重さまでいれることができる。このとき、袋にいれることができる荷物の組み合わせを求め、そのときの値段を求めなさい。
- 求めるのは、最大の値段だけでよい。(組合せは求めなくてもよい)
- 注意:Task構文は使わないこと
- ヒント:幅探索にする。
例:逐次再帰版
#define MAX_N 100
int N; /* データの個数 */
int Cap; /* ナップサックの容量 */
int W[MAX_N]; /* 重さ */
int P[MAX_N]; /* 価値 */
int main()
{
int opt;
read_data_file("test.dat");
opt = knap_search(0, 0, Cap);
printf("opt=%d\n", opt);
exit(0);
}
read_data_file(cha *file)
{
FILE *fp;
int i;
fp = fopen(file, "r");
fscanf(fp, "%d", &N);
fscanf(fp, "%d", &Cap);
for(i = 0; i < N; i++)
fscanf(fp, "%d", &W[i]);
for(i = 0; i < N; i++)
fscanf(fp, "%d", &P[i]);
fclose(fp);
}
int knap_search(int i,int cp, int M)
{
int Opt;
int l,r;
if (i < N && M > 0) {
if(M >= W[i]) {
l = knap_search(i + 1, cp + P[i], M - W[i]);
r = knap_search(i + 1, cp, M);
if (l > r) Opt = l;
else Opt = r;
} else
Opt = knap_search(i + 1, cp, M);
} else Opt = cp;
return(Opt);
}
- 行列
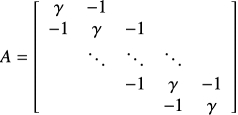
をCRS形式で保持するプログラムを作れ.
- CRS形式の行列ベクトル積を行うプログラムを作れ.
- 共役勾配法のプログラムを作り,連立一次方程式 Ax = b を解け.但し,b = A[1,1,...,1]Tとする.行列のパラメータは 2 < γ ≤ 4 に設定せよ.相対残差ノルムが || rk ||2 / || b ||2 ≤ 1.0 × 10-10 を満たしたら反復を停止すること.
- 複数のパラメータ γ について実験し,反復過程における相対残差ノルム || rk ||2 / || b ||2 をグラフにプロットせよ.
#include <stdio.h>
#define N 1000
int main(void)
{
static double a[N][N], b[N][N], c[N][N];
int i, j, k;
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
a[i][j] = rand(); b[i][j] = rand(); c[i][j] = rand();
}
}
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
for (k = 0; k < N; k++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
return 0;
}