プロセッサ・メモリ混載型LSI
― 現在の研究内容 ―
基本アーキテクチャ
SCIMA
今回提案するプロセッサは、シングルチップ内にロジック部および1次キャッシュだけでなく、アドレス指定可能な高速なオンチップメモリも搭載する。一般の科学技術計算における大容量のデータセットに対応するため、チップ外にもメインメモリとしてDRAMを配置する。
オンチップメモリと従来のキャッシュとの相違点は、データアロケーションとリプレースメントの制御がキャッシュでは自動的に行なわれるのに対し、オンチップメモリではその制御をソフトウェアで明示的に行える点である。この点から、提案するアーキテクチャをSCIMA(Software Controlled
Integrated Memory Architecture)と呼ぶ。ハードウェア制御のキャッシュでは、ユーザが意図しないデータアロケーション、リプレースメントによるキャッシュミスが発生することによる性能低下が問題となる。オンチップメモリを採用する狙いは、多くの科学技術計算がデータアクセスに規則性を持つことを利用し、ユーザ(あるいはコンパイラ)が明示的にデータアロケーションとリプレースメントを行なうことでこの問題を回避することである。

SCIMAの構成とデータ転送
上の図にSCIMAの構成を示す。以下にその概略を記し、次節でメモリ階層について述べる。
- PU全体
プロセッサ・メモリ混載型チップ、DRAM、NIA(ネットワークインタフェース)からなる。 - SCIMAチップ
スーパスカラアーキテクチャを基本とする。64ビット(場合によっては128ビット)浮動小数点演算器を仮定し、複数本(4以上)のパイプラインを持つとする。 - 混載されるメモリ
数MBから数10MB程度の高速SRAMを想定し、多バンク化ないし多ポート化して高いスループットを確保する。
メモリ階層
SCIMAでは、従来のアーキテクチャに対して、メモリ階層に関して以下の拡張を行う。
1.
浮動小数点レジスタを増やす
集積度の向上による搭載可能な演算器の増加とチップ内のキャッシュ/オンチップメモリの高バンド幅を活用するため
2.
オンチップメモリは論理アドレス空間上に定義する
オンチップメモリ上でのデータアロケーションとリプレースメントの制御をソフトウェアに解放するため。但しオンチップメモリ領域はuncacheableとするので、キャッシュとの包含関係は生じない。
追加命令
上記のメモリ階層の拡張を有効に利用するため以下の命令を追加する。
1. load-multiple,
store-multiple:
オンチップメモリの連続アドレス上と、連続するレジスタ間で複数データの転送を行う命令。オンチップメモリとレジスタの間に1000 bit程度のデー
タパスを設けることは将来的には可能と考えられるため、この命令の転送サイズとしては2,4,8,16 double-word程度を想定している。
2. page-load, page-store:
オフチップメモリとオンチップメモリ間でデータ転送を行なう命令。データ転送はページ単位で行う。この転送とチップ内部の計算処理とを重畳化することで、オフチップメモリアクセスのレーテンシを隠蔽する。また、ブロック幅とストライド幅を指定するブロックストライド転送の機能を付け加える。この機能により、オフチップメモリ上の不連続領域のデータをパッキングして、オンチップメモリに持ってくることを可能にする。
動作
大規模データを扱う科学計算におけるメモリ系の動作の概略は以下のとおりである。
- (1)計算に用いるページを、外付けDRAMからオンチップメモリに転送する(page-load)
- (2)計算に用いるデータを、オンチップメモリから、レジスタにload-multipleする
- (3)計算を実行する
- (4)計算結果のデータを、レジスタからオンチップメモリにstore-multipleする
- (5)計算結果の入ったページを、オンチップメモリから外付けDRAMに転送する(page-store)
以上の操作のうち、前のページのロード(1)と今のページの一連のload-multiple(2)は重畳化される。同様に、今のページの一連のstore-multiple(4)と前のページのストアは重畳化される。これをページレベルのパイプラインと呼ぶ。さらに、load-multiple, 計算実行、store-multipleは、転送サイズ(2~16double words)を単位として重畳化される。これを、語単位のパイプラインと呼ぶ。以上の2階層のパイプラインによって、高い処理スループットを得ることができる。本アーキテクチャでは、(1)外付けDRAMと混載SRAM間の高スループット転送、(2) (データ再利用による)混載SRAMとレジスタの間の高スループット低遅延転送、によって浮動小数点演算器の稼働率を高く保ち、高い性能を実現することを目指す。
シミュレータ開発
提案するSCIMAは既存アーキテクチャの拡張として定義可能であるが、本研究では具体的にはMIPSアーキテクチャをそのベースアーキテクチャとして採用する。これまでに、SCIMAの命令レベルシミュレータとクロックレベルシミュレータを作成した。前者は与えられた命令列を実行し結果が正しいかを確認するためのものであり、後者は与えられた命令列を実行するのに要するクロック数を求め性能を測定するためのものである。
最適化コンパイラ
SCIMAの内蔵SRAMは、ソフトウェアで制御するため、これを活かすには、コンパイラによるコード最適化が必須である。現在までに、
(1)SCIMA向けの言語仕様の拡張、(2)フロントエンドにおける最適化、(3) load-multiple、store-multiple,
page-load, page-storeという追加命令の生成手順、などを検討した。なお、ここでは言語としてCを用いている。
予備性能評価(平成10年度)
平成10年度はSCIMAの研究開発の立ち上げにあたり、(1) Livermore Kernelなどの基本ベンチマークを用いた解析、(2)予備的シミュレーション評価、の2点から行った。結果を以下に記す。
基本ベンチマークの解析
仮定したハードウェアは以下のとおりである。
- 内部クロック:2GHz
- I/Oクロック:1GHz
- 外付けメモリへのデータバス幅:512ビット(64B)
- 拡張命令:load-multiple(512ビット), store-multiple, page-load, page-store
- 浮動小数点用パイプライン:4本 (multiply and add × 4)
以上の仮定の下、以下の結果を得た。
- Livermore
1:
実効 8.2 GFLOPS/PU - Livermore
21 (C version):
実効10.6 GFOPS/PU
記憶系に新しい機構を導入することで、演算器の高い利用効率が得られた。
シミュレーション評価
平成10年度のシミュレーション評価では、既存のMIPSシミュレータを改善する形で、SPLASH, SPECといった標準的なベンチマークに対して、メモリ混載によるバンド幅の拡大による性能向上について調べた。結果の一部を図に示す。この結果によると、データがすべて混載メモリに乗って、メモリアクセス時間が大幅に減る場合には、最大で70%近い性能向上が得られることがわかった(Oceanベンチマークの場合)。
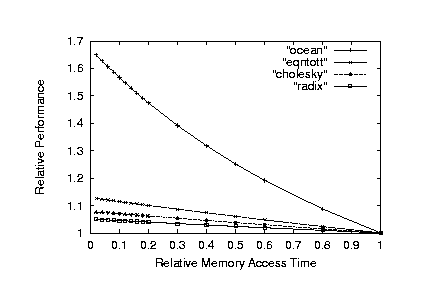
メモリ混載による性能向上のシミュレーション評価
(データがすべて混載メモリに載る場合)
以上の解析およびシミュレーション評価は、2004年のLSI(プロダクト技術)を基盤とし、SCIMAを用いて、実効で100 TFLOPS を越えるシステム(10000PU)を構築するための基礎データと位置づけられる。
基本性能評価(平成11年度)
QCD計算の解析
実アプリケーションであるQCD(量子色力学)計算を解析し、提案するアーキテクチャの有効性を検討した。この評価では、オンチップメモリとキャッシュのスループットを16
double-word/cycle、オフチップメモリのスループットを4double-word/cycleと仮定し、また演算能力として
(8mul+8add)/cycleと(16mul+16add)/cycleの2つの場合を想定し、計算に必要となる演算回数とメモリアクセス回数から性能を評価した。その結果を下図に示す。下図においては、横軸はオンチップメモリ容量を示し、縦軸は所要サイクルを示す。実線は演算能力が(8mul+8add)/cycleの場合を、点線は演算能力が
(16mul + 16add)/cycleの場合を示す。それぞれグラフが3本ずつあるのは、パラメータとしてキャッシュサイズを3通りに変化させたためである。

QCD計算における性能評価
実線と点線を比較することで、演算能力が(8mul+8add)/cycleの場合は演算能力が不足していて、キャッシュやオンチップメモリを増加させても性能が向上しないことがわかる。次に、このグラフのA点とB点の比較より、キャッシュを0MBから0.75MBに増加することは性能向上に大きく貢献すること、B点とC点の比較より、しかしキャッシュを0.75
MBから2.5MBに増加してもそれほどは性能向上に効かないことがわかる。また、C点 (キャッシュ2.5MB, オンチップメモリ0MB)とD点(キャッシュ0.75MB,
オンチップメモリ0.66 MB)とを比較することで、0.75MBのキャッシュがある場合には、キャッシュを増加するよりもオンチップメモリを増加した方が効果があることがわかる。
シミュレータを用いた行列積の評価
行列積の評価を、本年度開発したシミュレータを用いて行った。結果を下図に示す。評価では、キャッシュ32KBのみを持つ構成(図ではcache)とオンチップメモリ32KBと整数データ用のキャッシュ1KBを持つ構成 (図ではSCIMA) の性能を、行列サイズを変えながら求めた。それぞれの構成において、データアクセスの局所性を向上するブロッキング手法を取り入れて最適化を行っている。現在の実装技術の元でのオンチップメモリの効果を調べるため、演算能力は(1mul+1add)/cycle、キャッシュとオンチップメモリのスループットは1double-word/cycleでレーテンシは1サイクル、オフチップメモリのスループットは
0.5 double-word/cycleとした。オフチップメモリのレーテンシは0, 10,60 サイクルの3通りを仮定した。クロックは180MHzである。

行列積の性能
図より、SCIMAでは、オフチップメモリレーテンシの値に因らず高い性能を示すが、キャッシュの場合には、オフチップメモリレーテンシにより大きく性能
が低下する事がわかる。これは、オフチップメモリからブロックデータを転送する際に、SCIMAでは大きい粒度でpage load/storeを行っているためにレーテ
ンシの影響が小さいのに対し、キャッシュでは小さいラインサイズごとにレーテンシがかかるためである。
レーテンシ0cycleの場合、キャッシュはSCIMAの9割程度の性能となっている。理由は、SCIMAとキャッシュにおけるデータ転送量の違いである。キャッシュ
では、意図しないラインコンフリクトによるキャッシュミスのためデータ転送量が増加する。一方、SCIMAでは、データのリプレースメントをソフトウェア
制御するため、この様なコンフリクトによるメモリトラフィックの増加は発生しない。
レーテンシが0cycleの場合には、キャッシュにおいても高い性能が得られたが、レーテンシ60cycleの場合、キャッシュのMFLOPS値は、SCIMAのMFLOPS値の1/3程度となり、レーテンシ10cycleの場合でも7割の性能となっている。この様に、キャッシュの場合にはオフチップメモリアクセスレーテンシによって大きく性能が低下してしまう。レーテンシ10cycle程度のL2キャッシュをキャッシュ構成では載せることを想定し、SCIMA(latency=60cycle)とキャッシュ(latency=10cyce)を比較しても、キャッシュはSCIMAの7割程のMFLOPS値しか出ない。これは、従来のL1キャッシュとL2キャッシュから構成されるアーキテクチャより、SCMIAの方が性能的にも実装面積的にも有利であることを示している。
要素プロセッサに戻る
未来開拓のトップページに戻る