|
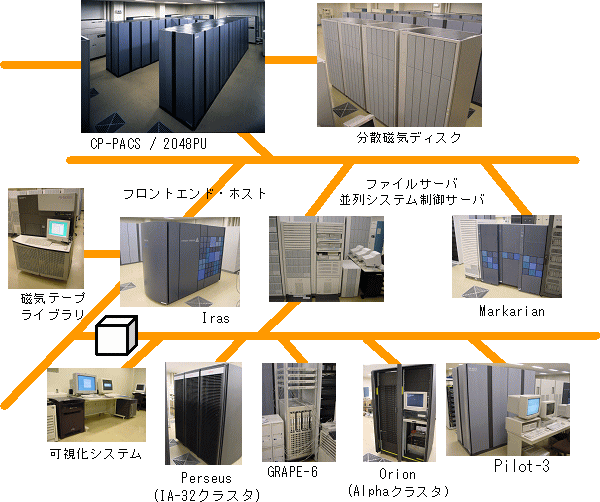
計算機設備
計算機システム
センター計算機システムは,超並列計算機CP-PACSとそのフロントエンド計算機システムを中心として構成されている。
フロントエンド計算機システムは,CP-PACSと並列プログラム開発用の小型並列システムPilot-3などを制御する並列システム制御用サーバ,CP-PACSによる生成データの解析と保管を行う解析サーバとファイルサーバ群,これらに連結された総容量2TByteの磁気ディスクと総容量16TByteのカートリッジ磁気テープライブラリ装置などの大容量外部記憶装置から構成されている。また,未来開拓学術研究推進事業「次世代超並列計算機開発」(平成9年度〜13年度実施)において開発実装した並列可視化システムやHMCS(異機種融合型複合計算機システム)のための重力計算専用機GRAPE-6,さらに各種のクラスタ計算機が整備されている。これらは,2系統のギガビットイーサネットによるLANにより接続され,相互に高速なデータ転送を可能としている。これらの計算機システムを駆使し,従来型のベクトル型処理に加え,クラスタ・専用計算機等の様々なプラットフォーム上での計算物理学研究が展開されている。
CP-PACSの稼動状況は,常時パフォーマンスモニタに表示されるとともに,遠隔監視システムによって監視されている。
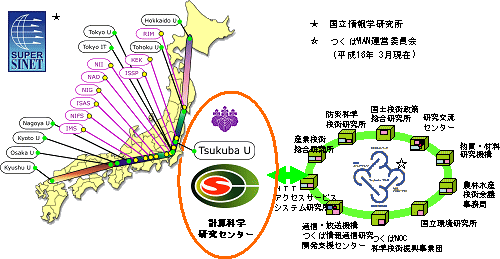
センターの対外ネットワーク環境
本学は平成14年10月より,10Gbpsの通信速度をもつ高速ネットワークであるスーパーSINETで国内の大学・研究機関と接続されている。さらに,筑波研究学園都市にある各省庁の研究機関を高速ネットワークで結合するつくばWANにも接続される。平成16年度において,本センターはスーパーSINETの専用実験線3本と,つくばWANグリッド実験線1本を有し,各種共同研究に利用している。これらのネットワークの接続点という立場を積極的に利用し,これまで超並列計算機CP-PACSでなされた計算結果の共有や,グリッドを用いた専用計算機GRAPEの利用など,計算機や計算データの共有による新たな計算物理の展開にグリッド技術を応用する研究を推進している。
PCクラスタによる計算物理学
PCなどに使われているマイクロプロセッサは,近年急激な進歩を遂げ,一般的に使われているPCでも十数年前のスーパーコンピュータに匹敵する性能を持つようになった。これらをコモディティネットワークで結合したクラスタは,従来の超並列コンピュータに匹敵する性能を達成している。本センターでは,高性能プロセッサを用いたクラスタを次世代の高性能並列計算プラットフォームの一つとして捉え,各種クラスタを実応用プログラムに用い,その性能評価を行うととともに,クラスタ向けのソフトウエア/ネットワーク技術の研究を行っている。さらに,各計算科学分野の諸問題をこれらのシステム上で効率的に処理するアルゴリズム/手法の研究も行っている。

PCベースクラスタシステム
超並列計算機 CP-PACS
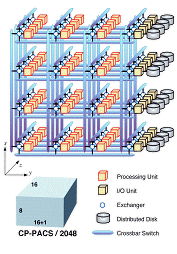
CP-PACSの全体構成
CP-PACSはMIMD (Multiple Instruction Multiple Data)方式の分散メモリ型並列計算機である。理論ピーク性能614Gflops、主記憶容量128Gbyteを持つ超並列計算機である。システムは、2048台の演算ユニット(PU:Processing Unit)(ピーク性能300Mflops、主記憶容量 64Mbyte)と,入出力を分散処理する128台のI/Oユニット(IOU:Input/Output Unit)からなり、これらが3次元ハイパークロスバー結合網により8x17x16の3次元配列に結合されている。 IOUはy方向クロスバーの一端のx-z面に設置されており、総容量529GbyteのRAID-5分散磁気ディスク装置が接続されている。
オペレーティングシステムはUNIXであり、プログラミングはFORTRAN90及びCによる。
CP-PACSは高い演算性能を持つことに加え,単体PU性能・結合網・入出力の全ての面でバランスのとれた超並列処理能力を備えている。

CP-PACS全景
高速ベクトル処理を実現する ノード・プロセッサ
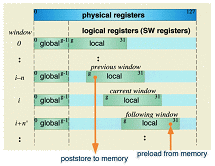
CP-PACSの各PUは,PA-RISC1.1アーキテクチャに基づく新規開発スーパースカラRISCプロセッサを搭載する。RISCプロセッサによる大規模科学技術計算では,データキャッシュの容量不足による演算性能低下が深刻な問題であるが,CP-PACSでは,これをPVP-SW (Pseudo Vector Processor based on Slide Window)機能の導入により解決している。
PVP-SWでは,論理レジスタ・ウィンドウを連続に切り替えるスライド・ウィンドウ機構により,多数の物理レジスタの利用を可能とする。また,擬似的にパイプライン化された主記憶に対して連続発行可能なPreload/Poststore命令により,先行ウィンドウへのロード,後続ウィンドウからのストアを行うことができる。これらのPVP-SW機能により,主記憶のアクセス遅延が隠蔽され,スーパースカラ・プロセッサでありながら,効率のよいベクトル処理が可能となっている。

ノードプロセッサモジュール
|
スライドウィンドウによる擬似ベクトル処理機構
|
高速データ転送を実現するハイパクロスバ結合網
CP-PACSの結合網は,多数のクロスバスイッチをX, Y, Z各方向に配列した3次元ハイパクロスバ(3-D Hyper Crossbar)を採用している。PUとIOUは各方向のクロスバを繋ぐExchangerに接続され,最大三段のクロスバを経由することにより,任意のパターンのPU間データ転送が可能であり,極めて柔軟な結合網となっている。データ転送はリモートDMA (Remote Direct Memory Access)方式により行われる。この方式では,OSの介在を最小限に抑え,各PU上のユーザ・メモリ領域間で直接データの送受信を行うことにより,転送立ち上げレイテンシの大幅削減と,高い転送スループット性能を実現している。
ネットワークと入出力システム
大容量分散磁気ディスクと高速外部入出力及びジョブ制御
科学技術計算においては,しばしば膨大な入出力を行う必要に迫られる。これを可能とするために,CP-PACSには,128台のIOUを通して,大容量のディスク装置が分散接続されている。ディスクには,耐故障性に優れたRAID-5規格が採用されている。各IOUは,多数のPUから生じるファイル入出力要求を,ハイパクロスバ結合網を用いて高速に並列処理することが可能である。
CP-PACSはHIPPIチャネルとETHERNETによりフロントホスト計算機に接続されている。フロントホスト計算機は、ピーク性能172Gflops、主記憶容量96Gbyteの超並列計算機であり、磁気ディスク装置(1.2TByte)及びカートリッジ磁気テープライブラリ(16TByte)を持つ。
CP-PACSと外部との入出力のためには,IOUの1台がHIPPIによりフロントホスト計算機と接続されており,大量のファイル転送を高速に行うことができる。また,16台のIOUが100base-TXイーサネットでディスクサーバに並列接続されている。
CP-PACSへのジョブ投入は、フロントホストを通じてNQSにより行われる。フロントホスト計算機の磁気ディスクとCP-PACSの分散磁気ディスクの間のユーザファイルの入出力は、HIPPIを通じて高速に行われ、計算結果出力は各ジョブの終了時にフロントホストの磁気ディスクに転送される。
CP-PACSについて、さらに詳しく知りたい方はこちらのCP-PACSプロジェクト「超並列計算機CP-PACSの概要」のページをご覧下さい。
小規模並列システム
並列プログラム開発用として,CP-PACSの小型モデルである小規模並列システム(Pilot-3)も設置されている。
ワークステーションとファイルサーバ
CP-PACSによる計算結果の解析のために,ワークステーションと,それらのワークステーションから利用するファイルサーバに接続されたRAID磁気ディスク装置,可視化のためのグラフィックワークステーションなどが整備されている。
|