|
Facilities
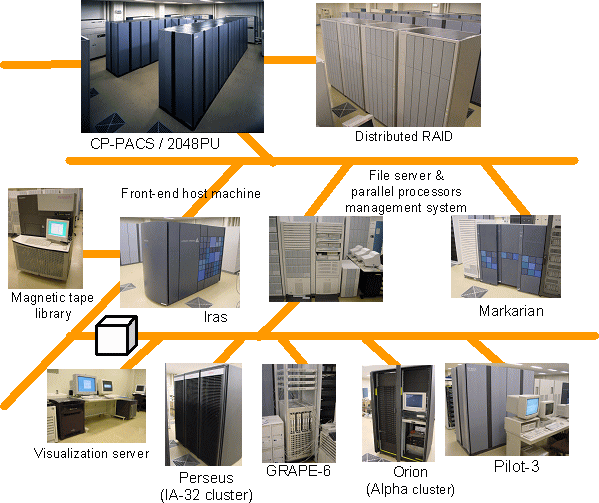
Computational Resources of the Center
The computational facilities consist of CP-PACS,a massively parallel processor, and surrounding front-end computer systems.
The front-end computer system includes Pilot-3 which is a small-sized CP-PACS, data analysis servers and file servers to analyze and save data produced by CP-PACS, a 2 TByte disk system and a 16TByte magnetic tape library. A parallelized visualization system, a special-purpose GrapE-6 parallel system for gravity calculation used for HMCS (Heterogeneous Multi-Computer System), and several PC-based cluster systems are also available. For data sharing based on Grid technology, 12 TByte of NAS RAID system is provided.
These facilities are connected with dual Gigabit Ethernet LAN for high speed data exchange among them. Using these facilities, a wide variety of research is being pursued in computational sciences using not only traditional vector processing schemes but also new scheme for clusters and special purpose machines .
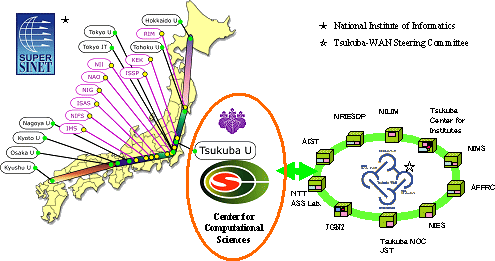
External network environment
University of Tsukuba is connected to Super-SINET, a 10Gbps nation-wide network which connects universities and research institutes under MEXT in Japan. It is also connected to Tsukuba-WAN which connects major research institutes under various ministries in Tsukuba Science City. The center has three dedicated links to Super-SINET for various experiments, and one dedicated link to Tsukuba-WAN for Grid research. As the junction point of these network links, we carry out wide variety of research based on Grid technology to share valuable data and computational resources. An important application is the archive of data produced by CP-PACS, the gravity special-purpose machince GRAPE-& and other resources.
Computational sciences by PC clusters
Recent remarkable progress of microprocessors used in PCs and workstations motivates high performance computing using clusters made of commodity microprocessors. As the performance of microprocessors becomes comparable to that of supercomputers a decade ago, the cluster of PC°«s connected by a commodity network can achieve similar or even higher, performance than traditional MPP systems.
While using these cluster systems to solve real computational physics problems, we also study performance of clusters as the high performance computing platform of next generation, and pursue new technologies on software and networking for them.

PC-based cluster systems
Massively parallel processor CP-PACS
Overview of CP-PACS
The CP-PACS is an MIMD (Multiple Instruction Multiple Data) parallel computer with a theoretical peak speed of 614 GFLOPS and a distributed memory of 128GByte. The system consists of 2048 processing units (PU' s) for parallel floating point processing and 128 I/O units (IOU' s) for distributed input/output processing. These units are connected together in an 8*17*16 three-dimensional array by a Hyper- Crossbar network. The well-balanced performance of the CPU, network and I/O devices supports the high capability of the CP-PACS for parallel processing.

Global view of CP-PACS
Node processor for high-speed vector processing
Each PU of the CP-PACS has a custom-made superscalar RISC processor with an architecture based on the PA-RISC 1.1. In large-scale computations in scientific and engineering applications on a RISC processor, the performance degradation occurring when the data size exceeds the cache memory capacity is a serious problem. For the processor of the CP-PACS, an upward compatible enhancement of the architecture, called the PVP-SW (Pseudo Vector Processor based on Slide-Window) has been developed.
In PVP-SW, it is available to utilize a large number of physical registers by sliding the logical register window. The access latency to a pseudo pipelined memory is hidden by continuously issued Preload/Poststore special instructions which can specify all physical registers as the target directly. With these features, an efficient vector processing is realized on its basic scalar architecture.

Node processor module
|
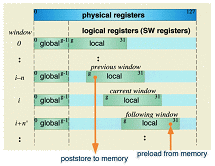
Pseudo-vector processing by sliding window
|
Hyper-crossbar network for high-speeddata exchange
The Hyper-Crossbar network of the CP-PACS is made of crossbar switches in the x-, y-, and z-directions connected together by an Exchanger at each of the three-dimensional crossing points of the crossbar array. Each Exchanger has a PU or IOU attached to it so that data transfer of any pattern is possible by stepping through a maximum of three crossbar switches. Data transfer through the network is made through Remote DMA (Direct Memory Access), in which data are sent or received directly between the user memory space of the processors with a minimum of intervention from the Operating System. This leads to a significant reduction in the start-up overhead and high effective throughput.
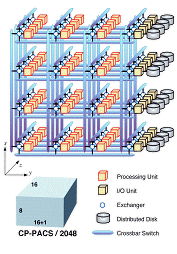
Network and disk I/O
Distributed disk system and external I/O
The distributed disk system of the CP-PACS is connected to 128 IOU°«s on the 8°þ16 plane at the end of the y-direction of the Hyper-Crossbar network by a SCSI-2 bus. RAID-5 disks are used for fault tolerance. The IOU°«s handle file I/O requests issued by the PU°«s in an efficient and distributed way using Remote DMA through the Hyper-Crossbar network.
For external I/O, one of the IOU°«s is connected to the front-end host by HIPPI. An Ethernet connection is also provided for system control without interrupting data transfer on HIPPI. In addition, 16 IOU°«s are connected to the disk and visualization servers through parallel 100 base-TX Ethernet.
More information about CP-PACS
Development of parallel computers and CP-PACS
Parallel computers have been the world°«s fastest computers since 1992, taking the title from vector supercomputers. Dedicated parallel computers developed for particle physics and other physics applications (red symbols) have played a significant role in this trend. The QCDPAX, which achieved 14GFLOPS in 1990, contributed much to particle physics, and paved the way toward the CP-PACS Project.
The CP-PACS computer started operation in March 1996 with 1024 processors (307GFLOPS). An upgrade to the final 2048 processor system, which achieved a peak speed of 614GFLOPS, was completed in September 1996. In November 1996, the CP-PACS was ranked No. 1 in the TOP 500 List of Supercomputers. The CP-PACS has been developed in collaboration with Hitachi Ltd.
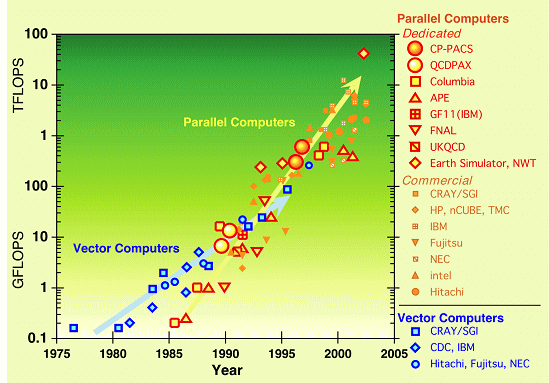
Performance of supercomputers
| 